The ipyrad.analysis module: RAxML
RAxML is the most popular tool for inferring phylogenetic trees using maximum
likelihood. It is fast even for very large data sets. The documentation for
raxml is huge, and there are many options. However, we tend to use the same small
number of options very frequently, which motivated us to write the ipa.raxml()
tool to automate the process of generating RAxML command line strings, running
them, and accessing the resulting tree files. The simplicity of this tool makes
it easy to incorporate into other more complex tools, for example, to infer
tress in sliding windows along the genome using the ipa.treeslider tool.
More information about RAxML can be found here and the scientific paper Stamatakis et al. (2014).
Input data
The raxml tool takes a phylip formatted file as input. In addition you can set
a number of analysis options either when you init the tool, or afterwards by
accessing the .params dictionary. You can view the raxml command string that is
generated from the input arguments and you can call .run() to start the tree inference.
Creating a new phylip file with min_samples_locus set to 10
In order to get RAxML to run in a reasonable amount of time we will repeat the final step of ipyrad, and adjust it so that we have fewer missing data. Remember that we’ve previously set min_samples_locus to 4, which means that ipyrad includes all SNPs which have data for at least 4 samples. This will result in a matrix which also includes lots of missing data, e.g. at positions where only 5 or 6 samples have data, but the SNP will still be included in the final output. To create an output file with fewer missing data (but also fewer SNPs!), we can increase min_samples_locus, e.g. to 10. However, we don’t want to overwrite the existing output files, so we’ll create a new “branch” of our assembly and re-run step 7 to generate new output files.
(ipyrad) osboxes@osboxes:~/ipyrad-workshop$ ipyrad -p params-cheetah.txt -b minsamples10
loading Assembly: cheetah
from saved path: ~/ipyrad-workshop/cheetah.json
creating a new branch called 'minsamples10' with 24 Samples
writing new params file to params-minsamples10.txt
This creates a new params file (as it says) which you should edit and modify to update the following parameter:
10 ## [21] [min_samples_locus]: Min # samples per locus for output
Now you can run step 7 again to generate the new output files with this new
min_samples_locus setting:
(ipyrad) osboxes@osboxes:~/ipyrad-workshop$ ipyrad -p params-minsamples10.txt -s 7 -c 4
This will create a new set of output files in minsamples10_outfiles which
have only retained loci present in 10 or more samples. Look at the stats file
to see how many loci are retained in this dataset? Do you think it will be fewer
or more than in the previous assembly with min_samples_locus set to 4?
A note on Jupyter/IPython
Jupyter notebooks are primarily a way to generate reproducible scientific analysis workflows in python. ipyrad analysis tools are best run inside Jupyter notebooks, as the analysis can be monitored and tweaked and provides a self-documenting workflow.
The rest of the materials in this part of the workshop assume you are running all code in cells of a jupyter notebook.
RAxML analyses
Create a new notebook for the RAxML analysis
In the jupyter notebook browser interface navigate to your ipyrad-workshop
directory and create a “New->Python” Notebook.
First things first, rename your new notebook to give it a meaningful name. You can
either click the small ‘disk’ icon in the upper left corner of the notebook or
choose File->Save Notebook and rename your notebook to “RAxML-peddrad.ipynb”
Import ipyrad.analysis module
The import keyword directs python to load a module into the currently running
context. This is very similar to the library() function in R. We begin by
importing the ipyrad analysis module. Copy the code below into a
notebook cell and click run.
import ipyrad.analysis as ipa
import toytree
The
as ipapart here creates a short synonym so that we can refer toipyrad.analysisasipa, which is just faster to type.
The following cell shows the quickest way to results using the small cheetah dataset (using min-samples-locus 10) we assembled earlier. Copy this code into a new notebook cell
(or use the small grey + button on the toolbar) and run it.
# Path to the input phylip file
phyfile = "minsamples10_outfiles/minsamples10.phy"
# init raxml object with input data and (optional) parameter options
rax = ipa.raxml(data=phyfile, T=4, N=2)
# print the raxml command string for prosperity
print(rax.command)
# run the command, (options: block until finishes; overwrite existing)
rax.run(block=True, force=True)
Note: In this block of code, the
#at the beginning of a line indicates to python that this is a comment, so it doesn’t try to run this line. This is a very handy thing if you want to add or remove lines of code from an analysis without deleting them. Simply comment them out with the#!
This runs for a minute or two…
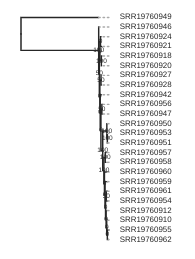
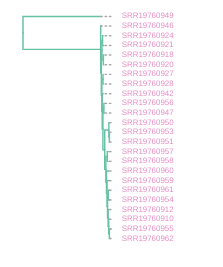
Draw the inferred tree
After inferring a tree you can then visualize it in a notebook using toytree.
# load from the .trees attribute of the raxml object, or from the saved tree file
tre = toytree.tree(rax.trees.bipartitions)
# draw the tree rooting on the P. concolor sample (SRR19760949)
rtre = tre.root(wildcard="SRR19760949")
rtre.draw(tip_labels_align=True, node_labels="support");
Making the tree readable
The tree you have now is pretty difficult to read, because all the cheetah samples have very low branch length. This is no surprise, because we know that cheetahs have very low diversity and are very similar to each other. However, it makes the interpretation of the tree difficult. We can, for now, also discard the information of the branch length, and just look at the topology of the tree.
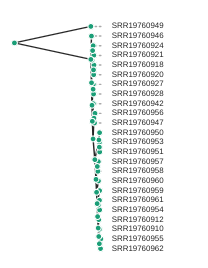
draw the showing topology only
rtre = tre.root(wildcard="SRR19760949")
rtre.draw(tip_labels_align=True, node_labels="support",use_edge_lengths=False);
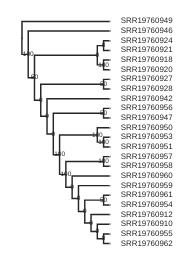
Coloring tip labels by sub-species identity
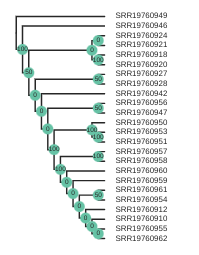
Now, we can actually see what samples group together. However, we don’t know all the sample codes by heart. We can assign colors to the labels, similar as we did in the PCA. Try running the following code:
imap = {"A.j.jubatus":['SRR19760918','SRR19760920','SRR19760921','SRR19760924','SRR19760927','SRR19760928','SRR19760942','SRR19760946','SRR19760947','SRR19760956'],
"A.j.soemmeringii":['SRR19760910','SRR19760912','SRR19760954','SRR19760955','SRR19760957','SRR19760958','SRR19760959','SRR19760960','SRR19760961','SRR19760962'],
"A.j.venaticus":['SRR19760950','SRR19760951','SRR19760953'],
"Outgroup":['SRR19760949']}
colormap = {"A.j.jubatus":"red",
"A.j.soemmeringii":"blue",
"A.j.venaticus": "teal",
"Outgroup":"black"}
colorlist = []
for sample in rtre.get_tip_labels():
for species, samples in imap.items():
if sample in samples:
colorlist.append(colormap[species])
rtre.draw(
tip_labels_align=True,
tip_labels_colors=colorlist,
use_edge_lengths=False
)

Setting parameters
By default several parameters are pre-set in the raxml object. To remove those
parameters from the command string you can set them to None. Additionally, you
can build complex raxml command line strings by adding almost any parameter to
the raxml object init, as below.
# parameter dictionary for a raxml object
rax.params
N 2
T 4
binary ~/miniconda3/envs/ipyrad/bin/raxmlHPC-PTHREADS-AVX2
f a
m GTRGAMMA
n test
p 54321
s ~/ipyrad-workshop/minsamples10_outfiles/minsamples10.phy
w ~/src/notebooks/analysis-raxml
x 12345
# Demonstrating setting parameters
rax.params.N = 10
rax.params.f = "d"
This will perform 10 rapid hill-climbing ML analyses from random starting trees, with no bootstrap replicates. 10 is a small value so it will run fast.
Styling the tree
The default plotted tree can be manipulated with toytree, which offers a huge
number of options for styling phylogenetic trees. A complete overview is available
in the toytree tree styling documentation
here we’ll just show a few of these.
# Add node labels showing node support
rtre.draw(node_sizes=15, node_labels="support", use_edge_lengths=False)
# Change the tree style
rtre.draw(tree_style='d') # dark-style
rtre.draw(tree_style='o') # umlaut-style
# Change the orientation
rtre.draw(tree_style="o", layout='d')
# Circle plot orientation
rtre.draw(tree_style="o", layout='c')
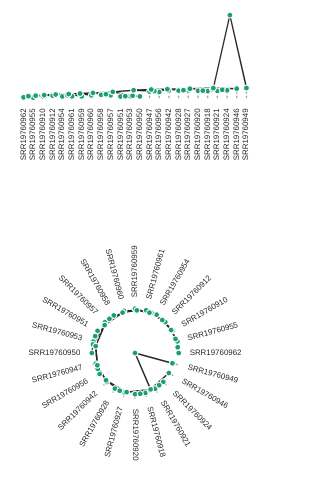
Again, much more is available in the toytree tree styling documentation.
Saving trees to pdf
Saving trees to pdf/svg/other output formats
More to explore
If the RADSeq assembly was performed with mapping to a reference genome
this creates the opportunity to perform phylogenetic inference within genomic
windows using blocks of RAD loci mapped to contiguous regions of a reference
chromosome. The ipyrad analysis toolkit provides window_extracter for doing
this (and more).
ipyrad-analysis toolkit: window_extracter
Window extracter has several key features:
- Automatically concatenates ref-mapped RAD loci in sliding windows.
- Filter to remove sites by missing data.
- Optionally remove samples from alignments.
- Optionally use consensus seqs to represent clades of multiple samples.